
I was really excited to read Google’s announcement of LiteRT-LM, their new inference runtime for running large language models directly on devices like Chrome, Chromebooks, and even Pixel Watches. (Google Developers Blog) The idea is to enable powerful AI features (summarization, chat, smart replies, etc.) without needing to call a remote server — so everything happens locally, with low latency, better privacy, and no per-API costs.
What I found especially interesting is how LiteRT-LM handles real technical challenges that I ran into myself. Recently I tried building a Chrome extension using Transformers.js — Hugging Face’s browser-based ML library that lets you run transformer models directly in the browser. I ended up crashing not just the browser, but the entire OS a few times, so I gave up. The memory requirements and execution model just weren’t stable enough for real browser environments.
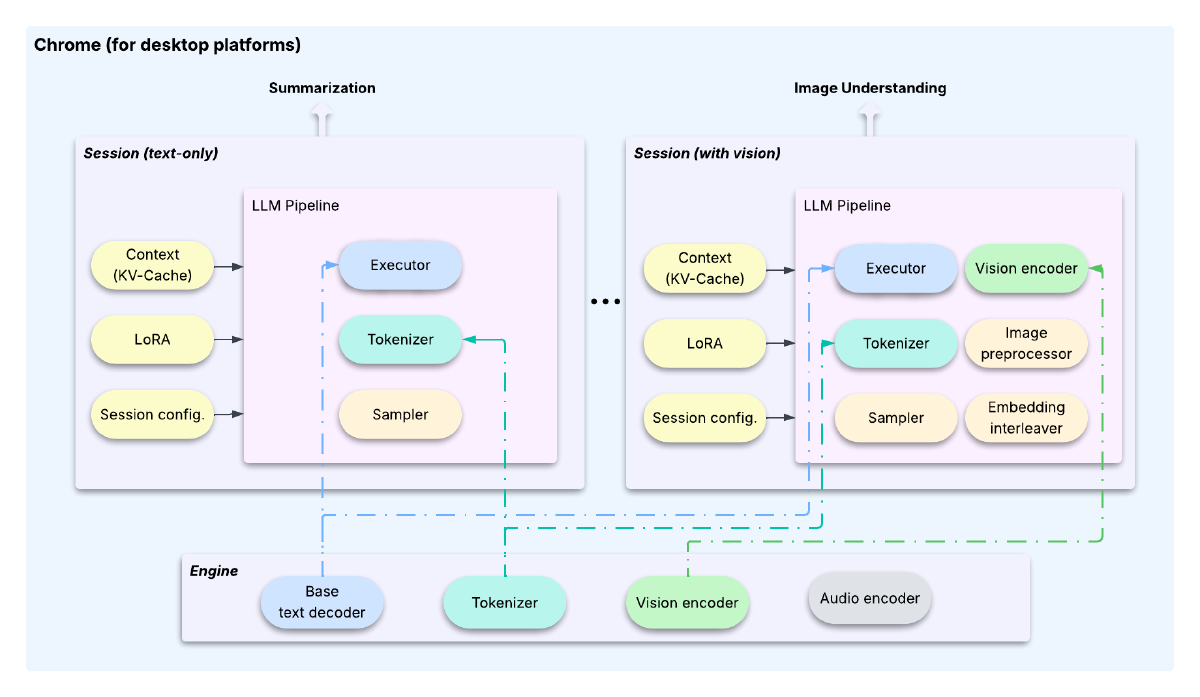
Google’s approach is fundamentally different. LiteRT-LM splits work into an Engine/Session architecture: the Engine holds shared, heavy resources (base model, tokenizers) and Sessions handle task-specific state (context, LoRA adapters). They use smart tricks like copy-on-write KV caches and session cloning, so you don’t waste memory or recompute from scratch.
This architectural approach addresses exactly what made libraries like Transformers.js unstable in production browser environments. While Transformers.js is incredible for experimentation and works well for lighter models, running full language models reliably in browsers has been challenging due to memory constraints and browser security limitations.
Because of that, this feels like a real path toward making on-device LLMs stable and usable in a browser environment — something that could finally beat the instability I saw with pure JavaScript libraries. I’m eager to try this approach in a Chrome extension and see whether it avoids the crashes I ran into before.
What this means for browser AI#
For developers like me who gave up on browser AI: This could finally make it viable. No more crashed browsers, no more memory exhaustion, no more unpredictable behavior.
For users: AI features that work instantly and privately — without sending your data to remote servers or waiting for API responses.
For the ecosystem: If Google can make on-device AI truly reliable, it changes the economics of AI applications. No API costs, no latency, no privacy concerns.
The question is whether this will create a two-tier AI experience — users with capable devices get instant, private AI, while others remain dependent on cloud services.
But honestly, after my experience crashing Chrome with Transformers.js, I’m just excited that someone might have figured out how to make browser AI actually work reliably.
Learn more: Google’s technical deep dive on LiteRT-LM, and Transformers.js documentation if you want to experiment with browser AI yourself.